Podcast: Machine Learning and Palliative Care Solutions

In this episode of the Oliver Wyman Health Podcast, Jeremy Powell, Chief Executive Officer of Acclivity Health, chats about how his company's machine learning and deep learning solution is helping physicians deliver appropriate palliative care. Jeremy shares some of his top solutions for better care delivery and explains what’s being done to ensure patients die on their own terms.
For this episode and more, check out the Oliver Wyman Health Podcast page, featuring executive conversations on the business of transforming healthcare, available on iTunes, iHeartRadio, Soundcloud, Google Play Music, Stitcher, and Spotify. Or, just tell Alexa, "Play Oliver Wyman Health Podcast."
Healthcare has spent the last decade deploying electronic records and building interoperability between technologies, but few of these capabilities are focused on addressing outcomes for the most complex patients. “Population Health” solutions provide insight around patient risk, utilization, and quality care, but few insights are packaged in meaningful ways for consumption by provider, patient or family stakeholders. These stakeholders will inevitably be empowered if we are to significantly bend trends related to clinical and financial outcomes.
The Institute of Medicine delivered a report back in 2010 that showcased $250 billion of healthcare spend was wasteful. “Left unchanged, healthcare will continue to underperform, cause unnecessary harm, and strain national, state, and family budgets," the panel wrote. "The actions required to reverse this trend will be notable, substantial, sometimes disruptive – and absolutely necessary."
Though problems facing healthcare constituents are systemic, studies show once our patient population faces advanced illness, only approximately half of patients that need palliative care are being referred for palliative services. Part of this stems from provider biases, part of it is owed to perverse reimbursement incentives that promote “over medicalized” care, and part is from lack of an organized method to ascertain which patients are appropriate for a palliative care referral.
We describe a method using machine learning to scan patients’ data and propagate the probability that they will die within the next 3, 6, or 12 months, or need palliative care due to a serious illness. The benchmark model has a 12 percent accuracy rate on predicting mortality. The average accuracy in the models described below is 90.3 percent. Our deep learning model proposes a solution for doctors struggling to provide appropriate palliative care to their patients with the most need.

Machine Learning Algorithms Propagate a Patient's Realistic Survival Rate
According to data from the National Palliative Care Registry™, in hospitals reporting palliative care teams, an average of 3.4 percent of admissions receive palliative care services. Estimates place the need for palliative care between 7.5 and 8 percent of hospital admissions. Accordingly, between 1 million and 1.8 million patients admitted to U.S. hospitals each year could benefit from palliative care but are not receiving it. We target this problem from a time and bias standpoint. Physicians do not have the time to work-up each patient’s entire record make real-time determinations about benefit potential from palliative care. Additionally, they have no simple, efficient way to compare each patient’s features to historical features of other patients. Finally, doctors often prognosticate a patient’s remaining time at three to five times greater than reality. Using machine learning algorithms, it is possible to automatically scan patient’s files against historical data and propagate a realistic survival rate for that patient. This allows for more accurate life expectancy estimates, less time taken to scan files manually, and more patients appropriately referred to a palliative program.

Methods and Metrics for Predicting Change of Survival
In order to screen patients who may need palliative care, a machine learning algorithm was used to assess patients who would be most likely to die within a 12-month period. It is hypothesized that patients who die within this period will have significantly more chronic and serious illnesses.
- True Positive (tp) - Set of patients who died, correctly predicted by the model.
- False Negative (fn) - Set of patients who died, incorrectly predicted by the model.
- True Negative (tn) - Set of patients who survived, correctly predicted by the model.
- False Positive (fp) - Set of patients who survived, incorrectly predicted by the model
- Accuracy - Accuracy provides information on how correctly both mortality and survival were predicted.
- Precision - Once Machine Learning model predicts list of patients who are likely to die, Precision tells how accurate that list is.
- Recall - Of all the patients who actually died, Recall identifies the percentage of patients that Machine learning model identifies correctly.
- True Negative Rate - Of all the patients who actually survived, True Negative Rate identifies the percentage of patients that Machine learning model identifies correctly.
The calculations for accuracy, precision, recall, and true negative rate are as follows:
Patients' survivability can be predicted using claims data and/or electronic health record (EMR) / electronic medical record (EMR) data. Categorization occurs as follows:
- From Claim and Claim Line Feed (CCLF) demographics Reports, find out all the patients who had an encounter with healthcare system.
- Those patients are categorized into 2 categories - patients who died and patients who survived.
- For each patient, the following categories of features were analyzed to ascertain the critical set of features required to build a machine learning model:
- Patient’s age, gender, race and Beneficiary Medical Status Code
- Patient’s claims data from facilities such as hospitals, SNFs (Skilled Nursing Facilities), HHAs (Home health agencies), rehabilitation facilities, dialysis facilities, acute care hospitals (inpatient and outpatient claims), and hospice facilities. Data included were Claim Type, Claim Facility Type, Principal Diagnosis, Admitting Diagnosis, Procedures, Patient Discharge Status Code, Patient Admission Type, and others.
- Patient’s claims data from physicians, practitioners, and suppliers. Data included were Provider Specialty, Principal Diagnosis and healthcare common procedures (based upon HCPCS)
- Patient’s prescription data

4. Machine learning model features were built as Time Series Data - For Time Series method, each feature (such as Admission, Procedure, and Diagnosis) was broken down by time. For example:
- Admission twice in last 3 months
- Admission once in 3 to 6 months
- Admission once between 9 to 12 months
- Admission twice a year ago
- Admission 4 times more than 2 years ago
5. Once features were finalized and all the data was available, multiple models using different Machine learning algorithm were implemented, analyzed singularly, and analyzed comparatively. Based upon the comparative analysis, results were published.
Here are the conclusive results:

All models do a good job of identifying patients who are likely to have mortality in next 3 to 12 months. Notice that Recall is between 32 to 45 percent. In the benchmark model, if you randomly pick up a patient and say that patient will die - you are likely to be correct 12 percent of the time. All machine learning models far outperform the benchmark model by 3-4 times.
Also note that all the models do very well in identifying patients who are going to survive. True Negative Rate is ~98 percent (compared to benchmark model of 88 percent) for all the models. So, palliative care providers can get a filtered list of patients (with precision up to 75 percent) who may need Palliative Care and don't need to go through records of entire list of patients.

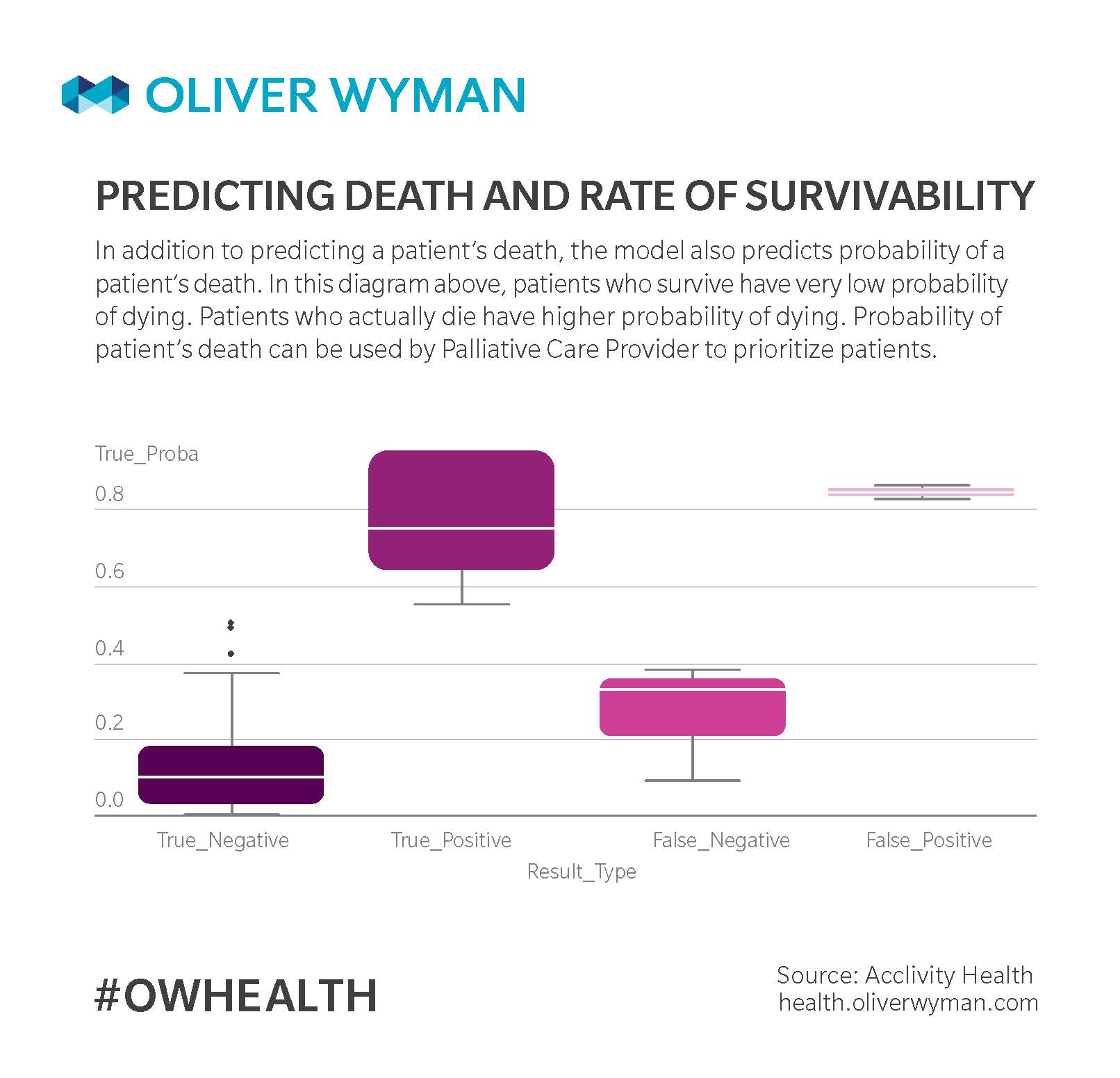
Predicting Probability of a Patient's Death to Help Physicians Prioritize Patients
In addition to predicting a patient’s death, the model also predicts probability of a patient’s death. In this diagram below, patients who survive have very low probability of dying. Patients who actually die have higher probability of dying. Probability of patient’s death can be used by Palliative Care Provider to prioritize patients.
Greater Implications for the Advancment of Palliative Care
Machine and deep learning models described here determine patients, who are likely to require palliative care. The need, though, is for this evidence to support the workflow of providers in their native settings using their native technologies. Most medical record software solutions support the ability to ingest evidence-based cues. It would significantly improve adoption if the outputs of such machine learning flowed directly into the chart of a patient at the point of care.
These advances and better use of current medical record technologies coupled with the use of machine learning prevents the provider from having to manually work-up and assess the severity of disease burden associated with each patient and removes any biases that may exist. This allows for a more accurate representation of the probability of a patient dying within a specified time frame. The probability rates can be used to prioritize patients, ensuring that the ones most in need receive palliative care immediately. This will diminish many costs associated with the most expensive care for the most complex patients while simultaneously providing better care to the patients with the most need.